Ce billet donne un aperçu de la notion de tables optimisées en mémoire (memory-optimized tables), concept incorporé à partir de la version 2014 de SQL Server,. Pour comprendre ce qu’est l’In-Memory OLTP, vous pouvez faire un saut ici.
Présentation des tables optimisées en mémoire
Notions de tables optimisées en mémoire
Les tables optimisées en mémoire sont des objets permettant un accès optimal aux données, en mémoire. Elles font partie de la fonctionnalité In Memory OLTP de SQL Server 2014 (minimum), également connu sous le nom de code Hekaton. La création de tables optimisées en mémoire se fait à travers l’utilisation d’un groupe de fichiers de type Memory_Optimized., sachant qu’un tel groupe de fichiers contient un ou plusieurs containers possédant, chacun, un ou plusieurs fichiers. Il existe 3 types de fichiers :
- Root file : il s’agit d’un fichier racine contenant des métadonnées incluant des fichiers de données et deltas, permettant ainsi de reconstruire les données en mémoire en cas de redémarrage d’une instance ou restauration de la base de données concernée. Un tel type de fichier est créé à chaque checkpoint (point de contrôle) de sorte qu’en cas de crash ou redémarrage, SQL Server soit en mesure de reconstituer les données en mémoire en combinant l’utilisation du journal des transactions avec le fichier de checkpoint.
-
Data file : il s’agit d’un fichier de données possédant des lignes de données ayant été insérées dans la table optimisée en mémoire concernée. Chaque fichier de données a une taille maximale de l’ordre de 128 Mo (avec organisation en page de 256 Ko), ce qui fait qu’au-delà de cette limite de taille, un nouveau fichier de données est créé, le fichier plein passant ainsi en lecture seule. Les lignes de données sont stockées avec une entête contenant le timestamp de la ligne pour le versioning (ce qui permet d’éviter les blocages), et N pointeurs d’indexes pour le chaînage de la ligne (où N est le nombre d’indexes définis dans la table, sachant que jusqu’à 8 indexes différents sont supportés).
Le schéma ci-dessous résume les explications :

- Delta file : ce type de fichier – organisé en pages de 4 Ko – contient les lignes de données ayant été supprimées. Pour chaque ligne supprimée, SQL Server insère l’identifiant des lignes supprimées et l’identifiant la transaction DML concernée, et leur timestamp de début et de fin de validité. Les fichiers delta sont stockées dans le journal des transactions, permettant ainsi un accès séquentiel.
Notons que :
- Quand une ligne de données est supprimée, elle reste inactive dans le fichier de données, jusqu’à ce que SQL Server lance un processus de fusion en arrière-plan permettant de consolider les paires de fichiers de données et delta en une seule paire.
- Les indexes ne sont stockés qu’en mémoire, ce qui fait qu’ils sont recréés à chaque redémarrage de l’instance ou restauration de la base de données cible, prolongeant ainsi les temps de récupération. Dans ce contexte, les indexes disposent d’une nouvelle structure de données : les BW-Trees.
Les types de tables optimisées en mémoire
Il existe 2 sortes de tables optimisées en mémoire : SCHEMA_AND_DATA et SCHEMA_ONLY. Les tables de type SCHEMA_AND_DATA sont des tables stockées en mémoire avec des données disponibles, y compris après sinistre ou arrêt/redémarrage d’un serveur. Les tables de type SCHEMA_ONLY, quant à elles, sont des tables dont les données ne sont plus disponibles en mémoire après sinistre ou arrêt/redémarrage du serveur, contrairement à leurs structures. Chacun de ces deux types de tables ont des avantages qui leur sont propres. Ainsi l’un (SCHEMA_AND_DATA) est plus utile dans un contexte où la perte de données transactionnelles n’est pas souhaitée après un crash ou un redémarrage de l’instance, tandis que l’autre (SCHEMA_ONLY) sied mieux dans le cas de tables à utiliser dans pour des traitements intermédiaires (contexte ETL, par exemple). Le type SCHEMA_AND_DATA est l’option par défaut utilisée par SQL Server lors de la création d’une table optimisée en mémoire. A partir de SQL Server 2014, le catalogue système sys.tables permet de capturer les informations sur la durabilité des tables optimisées en mémoire :
SELECT name
,type_desc
,durability_desc
FROM sys.tables
GO
| Le Memory Optimization Advisor peut permettre de déterminer les tables qui pourraient bénéficier de bonnes performances d’accès dans le cas d’une migration vers In-Memory OLTP. |
Principales limitations
Comme toute fonctionnalité qui se respecte, les tables optimisées en mémoire possèdent, bien sûr, quelques limitations, dont voici une liste non-exhaustive :
- Non-support de clés étrangères.
- Non-support de contraintes de vérification CHECK ou d’unicité UNIQUE (hors clé primaire).
- Non-support de triggers DML.
- Non-support d’une colonne d’identité, sauf à partir de SQL Server 2016.
- Non-support de requêtes DDL de modification (ALTER TABLE), sauf à partir de SQL Server 2016.
- Non-support de la troncature (TRUNCATE TABLE).
- Non-support de certains types de données, et principalement les LOB (Large Object Binary), qui ne sont supportés qu’à partir de SQL Server 2016.
- Ne supporte que les collations de type BIN2 (principalement pour des raisons de performances), sauf à partir de SQL Server 2016 où toute collation est supportée.
- …
Plus de détails ici: https://msdn.microsoft.com/en-us/library/dn246937.aspx?f=255&MSPPError=-2147217396.
Utilisation technique de tables optimisées en mémoire
Création de tables optimisées en mémoire
Avant de pouvoir utiliser une table optimisée en mémoire, il faut soit s’assurer que la base de données existante supporte les tables optimisées en mémoire, soit en créer une nouvelle contenant un groupe de fichiers filestream pour le support d’une telle fonctionnalité. Ou la modifier – via ALTER DATABASE – pour inclure un tel groupe de fichiers. Créons une base de données InMemoryDB :
IF EXISTS (SELECT * FROM sys.databases WHERE name = N'InMemoryDB')
DROP DATABASE InMemoryDB
GO
CREATE DATABASE InMemoryDB
ON PRIMARY
(NAME = InMemoryDB_Data,
FILENAME=N'D:\SQL Server\MSSQL2014\SQL\SQL Data\InMemory_Data.mdf',
SIZE = 250MB,
FILEGROWTH = 100MB),
FILEGROUP InMemoryDB_InMemoryDB CONTAINS MEMORY_OPTIMIZED_DATA
(NAME = InMemoryDB_InMemoryDB,
FILENAME=N'D:\SQL Server\MSSQL2014\SQL\SQL Data\InMemoryDB_InMemoryDB.mdf')
LOG ON
(NAME = InMemoryDB_Log,
FILENAME = N'D:\SQL Server\MSSQL2014\SQL\SQL Logs\InMemory_Log.ldf',
SIZE = 100MB,
FILEGROWTH = 50MB)
GO
Le filegroup nommé InMemoryDB_InMemoryDB « active » de facto l’utilisation de tables optimisées en mémoire. En cas d’utilisation de SQL Server Management Studio (SSMS), il suffit d’aller dans la section Filegroups des propriétés de création ou de modification de la base de données cible, puis d’ajouter le filegroup dans la section MEMORY_OPTIMIZED DATA :

La base de données prête, créons une table optimisée en mémoire :
- Durable (SCHEMA_AND_DATA) :
IF OBJECT_ID('InMemoryTableData','U') IS NOT NULL
DROP TABLE InMemoryTableData
GO
CREATE TABLE InMemoryTableData
(InMemoryTableData_ID INT NOT NULL,
InMemoryTableData_Name VARCHAR(255) NOT NULL,
CONSTRAINT PK_InMemoryTableData PRIMARY KEY NONCLUSTERED HASH (InMemoryTableData_ID) WITH (BUCKET_COUNT = 100000)
)
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)
GO
- Non-durable (SCHEMA_ONLY) :
IF OBJECT_ID('InMemoryTableSchema','U') IS NOT NULL
DROP TABLE InMemoryTableSchema
GO
CREATE TABLE InMemoryTableSchema
(InMemoryTableSchema_ID INT NOT NULL,
InMemoryTableSchema_Name VARCHAR(255) NOT NULL,
CONSTRAINT PK_InMemoryTableSchema PRIMARY KEY NONCLUSTERED HASH (InMemoryTableSchema_ID) WITH (BUCKET_COUNT = 100000)
)
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY)
GO
Ci-dessus, on peut noter la présence de nouvelles options de création d’une table, avec notamment :
- MEMORY_OPTIMIZED, qui permet de définir la table en tant que table optimisée en mémoire.
- DURABILITY, qui permet de spécifier le type de table optimisée en mémoire (ici, SCHEMA_AND_DATA, afin d’assurer la permanence des données en mémoire).
- HASH(InMemoryTable_ID) qui permet de créer un index de hachage sur la colonne InMemoryTable_ID de la table. Avec l’option BUCKET_COUNT spécifiée à 100000, permettant à SQL Server de construire 100000 buckets différents destinés à recevoir les données de la table en mémoire. Il est recommandé d’attribuer une valeur de BUCKET_COUNT suffisamment large (approximativement 2 fois le nombre de clés d’index attendu, sachant qu’il est habituellement plus commode d’attribuer une valeur supérieure ou égale à 1000).
Et côté SSMS ? Rien de bien compliqué, sachant qu’une image vaut mille mots :

Cela aura pour effet de générer un modèle de script de création d’une table optimisée en mémoire, qu’il faudra adapter en fonction des besoins.
Opérations DML sur une table optimisée en mémoire et comparaison avec une table basée sur disque
Afin d’avoir un référentiel de mesure significatif concernant les insertions sur la table optimisée en mémoire, créons une table basée sur disque :
IF OBJECT_ID('OnDiskTable','U') IS NOT NULL DROP TABLE OnDiskTable
GO
CREATE TABLE OnDiskTable
(OnDiskTable_ID INT NOT NULL,
OnDiskTable_Name NVARCHAR(255) NOT NULL,
CONSTRAINT PK_OnDiskTable PRIMARY KEY CLUSTERED (OnDiskTable_ID))
GO
Le script ci-dessous permet de charger près de 100 000 enregistrements aléatoires dans chaque table : InMemoryTableData, InMemoryTableSchema et OnDiskTable :
USE InMemoryDB GO /** Variable declarations **/ DECLARE @i INT, @d DATETIME; /** Processing InMemoryTableData **/ SET @i=0 SET @d=GETDATE() WHILE @i < 100000 BEGIN SET @i+=1; INSERT INTO InMemoryTableData(InMemoryTableData_ID,InMemoryTableData_Name) VALUES (@i,CONVERT(VARCHAR(10),CAST(NEWID() AS VARBINARY(16)),2)); END; SELECT DATEDIFF(s,@d,GETDATE()) AS 'InMemoryTableData'; /** Processing InMemoryTableSchema **/ SET @i=0 SET @d=GETDATE() WHILE @i < 100000 BEGIN SET @i+=1; INSERT INTO InMemoryTableSchema(InMemoryTableSchema_ID,InMemoryTableSchema_Name) VALUES (@i,CONVERT(VARCHAR(10), CAST(NEWID() AS VARBINARY(16)),2)); END; SELECT DATEDIFF(s,@d,GETDATE()) AS 'InMemoryTableSchema'; /** Processing OnDiskTable **/ SET @i=0 SET @d=GETDATE() WHILE @i <= 100000 BEGIN SET @i+=1; INSERT INTO OnDiskTable(OnDiskTable_ID,OnDiskTable_Name) VALUES (@i,CONVERT(VARCHAR(10), CAST(NEWID() AS VARBINARY(16)),2)); END; SELECT DATEDIFF(s,@d,GETDATE()) AS 'OnDiskTable'; GO
Côté temps de réponse, sachant que les tests ont été effectués sur une machine dotée de 8 Go de RAM et 4 CPUs (avec MAXDOP bridé à 2), cela donne :
- InMemoryTableData : 42 secondes.
- InMemoryTableSchema : 4 secondes.
- OnDiskTable : 50 secondes.
On peut déduire que les temps d’exécution sont en faveur des tables optimisées en mémoire. De plus, le fait que la table non-durable (InMemoryTableSchema) possède un temps plus court que celui de la table durable s’explique par le fait que dans cette dernière, le moteur InMemory OLTP a besoin d’effectuer des opérations I/O supplémentaires utilisant les fichiers checkpoint (fichier de données et fichier delta qui forment une paire appelée CFP, ou Checkpoint File Pair) et le journal des transactions afin de garantir la récupération des données en cas de redémarrage de l’instance ou restauration/récupération de la base de données InMemoryDB. Il apparaît donc logique que ces opérations impactent les temps d’insertion.
Test de durabilité
En parlant justement de récupération de la base de données, si l’on simule un redémarrage de l’instance afin de tester la durabilité des données :

On retrouvera la base InMemoryDB en mode de récupération, le temps que les données de la table durable soient chargées en mémoire. Et dans l’errorlog, quelques messages informatifs feront leur apparition :

En consultant la table InMemoryTableData, on retrouve les données insérées avant le redémarrage, dont voici un extrait :

En revanche, dans le cas de la table InMemoryTableSchema, le contenu est vide :
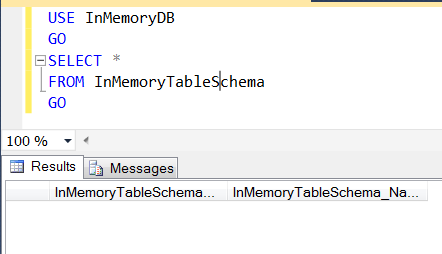
Moralité : bien que les temps de chargement de données dans une table durable optimisée en mémoire sont moins rapides que dans une table non-durable optimisée en mémoire, la table durable offre la possibilité de récupérer les données en mémoire en cas de sinistre.
Génération…
…des fichiers DDL
La création des tables optimisées en mémoire génère des fichiers DLL utiles au moteur In-Memory OLTP pour le traitement des données en mémoire, et préfixées d’un « xtp_t ». Les fichiers sont généralement placés dans un dossier xtp\<Identifiant_de_la_base>, au sein du dossier où sont stockés les fichiers de données de la base où se trouve(nt) les tables cibles optimisées en mémoire. Dans notre cas, D:\SQL Server\MSSQL2014\SQL\SQL Data\xtp\8 (où 8 est l’identifiant de la base, aisément identifiable dans sys.databases, par exemple):

La requête ci-dessous, utilisant la DMV sys.dm_os_loaded_modules peut permettre d’identifier les fichiers DDL générés (avec leur chemin d’accès) :
SELECT name
,description
FROM sys.dm_os_loaded_modules
WHERE description='XTP Native DLL'
GO
Ce qui donnera le résultat suivant :

Soit autant de fichiers DLL que de tables optimisées en mémoire créées.
… des fichiers checkpoint
Concernant les fichiers checkpoint,nous avons vu dans un billet précédent que des paires de fichiers checkpoint (ou CFP, pour Checkpoint File Pairs : paires de fichiers de données et delta) sont utilisées pour permettre la récupération de données en cas de redémarrage d’une instance, la mémoire étant par essence volatile. Leur utilisation par le moteur In-Memory OLTP concerne principalement les tables durables optimisées en mémoire (créées avec l’option SCHEMA_AND_DATA). Chaque fois qu’une transaction est validée, le moteur In-Memory OLTP les archive dans le journal des transactions. Et chaque fois qu’un checkpoint est lancé, les données sont déplacées du journal des transactions vers le groupe de fichiers filestream, au sein du container du checkpoint où sont stockées la paire de fichiers de données et delta. De cette façon, lors de la phase de récupération de la base de données concernée (après redémarrage de l’instance ou restauration, par exemple), les données issues de ces fichiers sont alors récupérées, avec la portion active du journal des transactions, pour reconstruire le contenu de la table optimisée en mémoire à un état suffisamment à jour. On rappelle qu’un fichier de données (~128 Mo) contient les données insérées et qu’un fichier delta contient des marqueurs pointant sur des données supprimées. Et qu’en cas de modification d’une données, sa précédente version est supprimée (marquée dans le delta) et sa nouvelle ajoutée (dans le fichier de données). La DMV sys.dm_db_xtp_checkpoint_files peut être utilisée pour connaître les CFPs exploités pour la durabilité d’une table optimisée en mémoire. Si l’on reprend notre exemple sur la base InMemoryDB, on peut lancer la requête DMV comme suit :
USE InMemoryDB
GO
SELECT file_id
,pair_file_id
,file_type_desc
,relative_file_path
FROM sys.dm_db_xtp_checkpoint_files
ORDER BY file_id desc
GO
Dont voici un exemple de résultat :
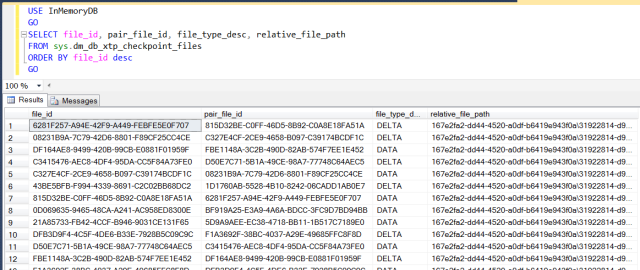
Les informations affichées par la DMV font référence aux métadonnées des fichiers checkpoint maintenus par le moteur In-Memory OLTP. La colonne file_type_desc permet de déterminer s’il s’agit d’un fichier de données ou d’un fichier delta tandis que la colonne relative_file_path donne le chemin d’accès du container checkpoint au sein duquel les CFPs sont stockés. Le dossier des CFPs est stocké au sein du dossier relatif au groupe de fichiers filestream (si l’on reprend notre exemple de création dudit groupe de fichiers, en début de billet : D:\SQL Server\MSSQL2014\SQL\SQL Data\InMemoryDB_InMemoryDB.mdf). Ainsi, si l’on prend la première ligne de relative_file_path du résultat de notre requête DMV ci-dessus (jusqu’au dernier backslash « \ »)…
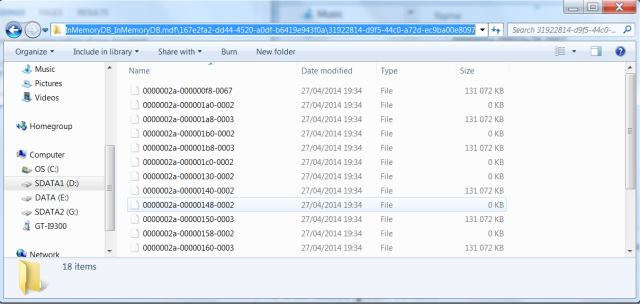
| 167e2fa2-dd44-4520-a0df-b6419e943f0a\31922814-d9f5-44c0-a72d-ec9ba00e8097\0000002a-00000130-0002 |
… et qu’on complète le chemin d’accès du dossier du groupe de fichiers filestream avec, on obtient cet exemple de résultats, avec le contenu de tous les fichiers de données et delta (nous pouvons apercevoir le fichier delta 0000002a-00000130-0002) :
Dans un billet dédié, quelques éléments pratiques sur les CFPs (i.e., cycles de vie, opérations de fusion,…) seront traités plus en détail.
Pour aller plus loin…
Ce billet a permis d’avoir un aperçu de ce qu’est une table optimisée en mémoire. Gardez œil ici pour d’autres billets sur le même sujet, notamment du point de vue des performances et de la gestion des collisions. Vous pouvez également jeter un coup d’œil ici, pour plus de lectures : http://msdn.microsoft.com/en-us/library/dn511014.aspx.
