Ce billet présente comment mettre-en-place la réplication de fusion (merge replication) avec SQL Server 2008 (R2) – globalement le même mode opératoire que pour les versions 2012 et 2014 -, via SQL Server Management Studio (SSMS). Pour comprendre les différents concepts associés à la réplication de fusion, vous pouvez aller ici, et pour les prérequis, vous pouvez aller là.
A noter qu’avant de commencer, il faudra configurer un distributeur comme vu ici.
Contexte de nos besoins
Pour nos exemples de mise-en-place, nous allons configurer un mécanisme de réplication :
- Réplication entre une base MaBase1 et deux autres bases MaBase5 et Mabase3 en ne répliquant qu’une partie de MaBase1 (tables MaTable1 et MaTable2, vue MaVue2, procédures stockée usp_SP2) vers MaBase5 et une autre partie de MaBase1 (tables MaTable1 et MaTable3, vue MaVue3, procédures stockée usp_SP3) vers MaBase3.
- Exemple de besoin dans le monde réel : rafraîchissement quotidien de bases de données (filles) distribuées, imprévisiblement offline (cas des applications mobiles) et pouvant envoyer des modifications vers la base mère.
-
Planification des agents de réplication souhaitée pour notre exemple :
- Snapshot Agent : tous les jours, à minuit.
- Merge Agent : chaque jour, en continu pour la base abonnée MaBase5 (de type « Serveur ») et à la demande pour la base abonnée MaBase3 (de type « Client »).
- Snapshot Agent : tous les jours, à minuit.
| Le choix des planifications des agents des différents types de réplication sont, ici, bien sûr des exemples. En temps normal, il faudra les adapter en fonction de divers facteurs : les besoins en termes de synchronisation, la charge sur les serveurs, etc… |
Du côté des structures de données :
- MaBase1 possède 4 tables MaTable1, MaTable2, MaTable3 et MaTable4, 3 vues MaVue1, MaVue2 et MaVue3, 3 procédures stockées usp_SP1, usp_SP2 et usp_SP3.
- MaBase3 possède 3 tables MaTable1, MaTable2 et MaTable3, 2 vues MaVue1 et MaVue3, 2 procédures stockées usp_SP1 et usp_SP3.
- MaBase5 possède 2 tables MaTable1 et MaTable2, une vue MaVue2 et une procédure stockée usp_SP2.
Du côté de la localisation des bases de données :
- MaBase1 est placée sur l’instance SRV-SQL01 qui fera figure d’éditeur (et de distributeur).
- MaBase5 sont sur SRV-SQL02.
- MaBase3 est sur SRV-SQL03.
Notons que :
Et supposons que :
|
Modus operandi de mise-en-œuvre de la réplication de fusion
Pour la mise-en-œuvre du mécanisme de réplication de fusion, procédons comme suit sur SRV-SQL01 (futur éditeur) :
-
Lancement de l’assistant de création de la publication :

Une fenêtre de bienvenue s’ouvrira :
-
Sélection de la base MaBase1 comme base de publication :
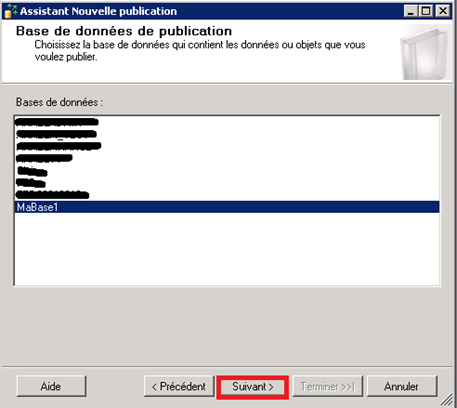
-
Choix du type de réplication : réplication de fusion :
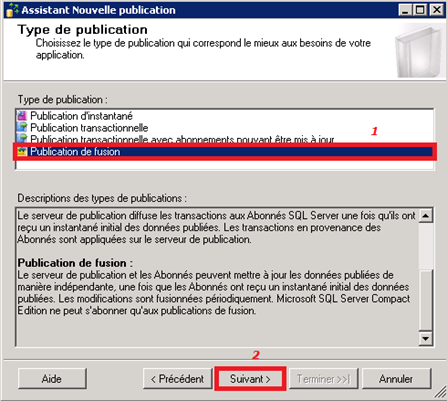
-
Choix du type d’abonnés :
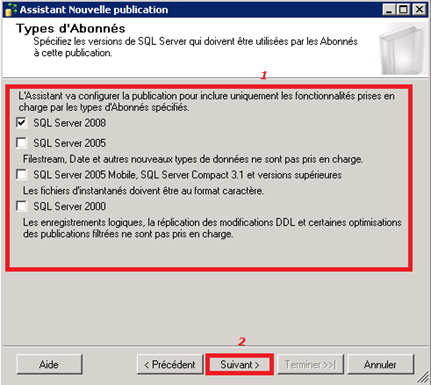
Nos bases étant du MSSQL 2008 (niveau de compatibilité 100), on opte alors pour SQL Server 2008.
-
Choix des articles suivant les besoins et définition de leurs propriétés (dont la direction de la synchronisation et le mode de résolution de conflits) :
- Choix des articles :
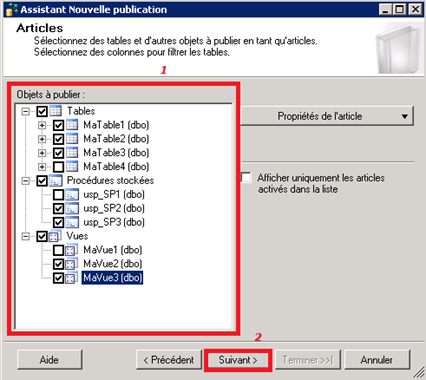
On choisit les bons articles à répliquer suivant nos besoins.
- Définition de propriétés :
Rappelons qu’à l’instar de ce qui a été évoqué dans le cas de la réplication de snapshot, il est possible d’éventuellement définir les propriétés de chaque article (ou d’un ensemble d’articles de même type). Exemple pour l’ensemble des tables (il suffit de mettre en surbrillance n’importe quelle table sélectionnée) :

Un clic sur Définir les propriétés de tous les articles de Table ouvre la boîte modale suivante :
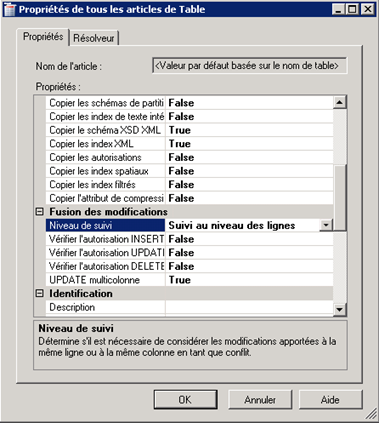
Contrairement aux autres types de réplication, on peut noter la présence d’un groupe Fusion des modifications dont le but est de déterminer le comportement du Merge Agent face à un conflit de mise-à-jour (insertion, modification ou suppression), et à quel niveau (lignes ou colonnes) il doit s’y intéresser.
En règle générale, les valeurs par défaut sont largement suffisantes.
D’ailleurs, en faisant un scroll up, on peut noter que toutes les contraintes et indexes non-clusters sont copiés par défaut :
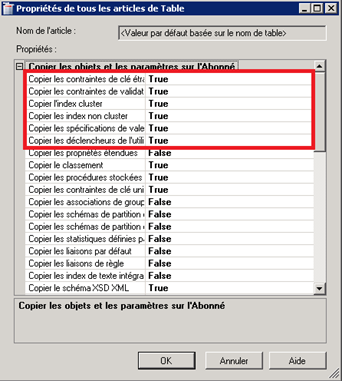
- Choix des articles :
| Soulignons qu’en aucun cas que la réplication de fusion copiera les indexes, les contraintes,… : c’est le snapshot qui le fera (s’il est lancé manuellement ou automatiquement). |
Une bonne pratique générale consiste à créer manuellement ces structures de données (via génération de scripts sous SSMS sur l’éditeur, par exemple) sur les bases abonnées concernées de façon à ne pas avoir à lancer un nouveau snapshot si celui-ci s’avère long et coûteux.
On peut également copier les autres types d’indexes (filtrés, XML, spatiaux,…) et éventuellement (mais ce n’est pas le cas dans notre exemple) les autorisations d’accès aux objets (assurez-vous, dans ce cas, que les bons logins et utilisateurs existent sur les abonnés concernés), ainsi que le classement ou collation (en partant du postulat que l’on souhaite que les abonnés aient la même collation que l’éditeur, mais dans notre exemple, ce besoin est ignoré).
Par ailleurs, pour les vues, on choisit de copier les triggers et propriétés étendues, tout en laissant les autres propriétés intactes :
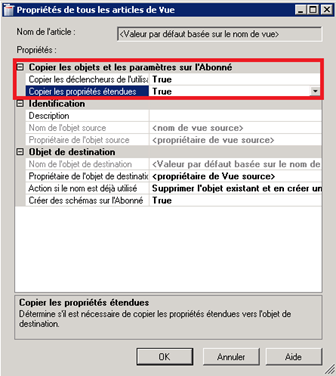
Et pour les procédures stockées, les propriétés étendues tout en laissant les autres propriétés intactes.
- Choix de la direction de synchronisation :
Toujours au sein de la même fenêtre de propriétés, en faisant un scroll down, on peut apercevoir un groupe Objet de destination au sein duquel se trouve une option Direction de la synchronisation :
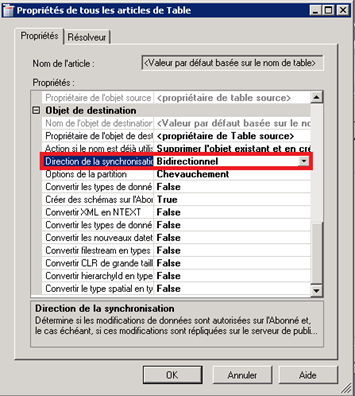
Par défaut, la valeur est à Bidirectionnel ce qui signifie que des mises-à-jour au sein des abonnés sont possibles et « réplicables » vers l’éditeur. Dans notre exemple, nous laissons cette valeur telle quelle.
Si vous souhaitez que certaines tables spécifiques ne soient pas modifiées par un abonné, vous pouvez mettre la table concernée en surbrillance, puis cocher Cette table est en téléchargement seul :
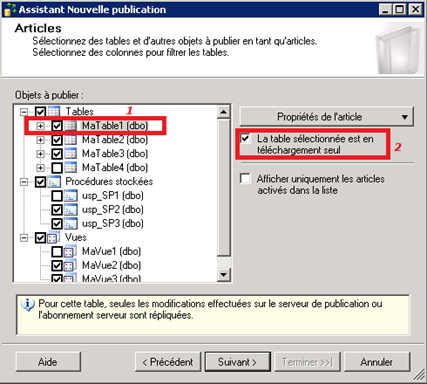
Dans notre exemple, c’est la table MaTable1 que l’on ne souhaite pas rendre modifiable par les abonnés contrairement aux autres.
- Choix du resolver de conflits :
Au sein de la fenêtre de propriétés des tables, on peut choisir le mode de résolution des conflits en accédant à l’onglet Résolveur :

Vu qu’aucun custom resolvers (voir billet [SQL Server] Réplication : fonctionnement de la réplication de fusion) n’a été configuré et enregistré dans le distributeur, le choix se fait entre : l’utilisation du resolver par défaut (comparaison des niveaux de priorités des abonnés) et le fait d’autoriser chaque abonné concerné à résoudre les conflits de manière interactive au cours de la synchronisation à la demande.
En laissant le dernier choix décoché, on opte alors pour la résolution par défaut.
Le niveau de priorité des abonnés sera définit durant leur configuration, plus loin.
-
Lisez l’avertissement de l’assistant qui parle du référencement des articles et autres contraintes :
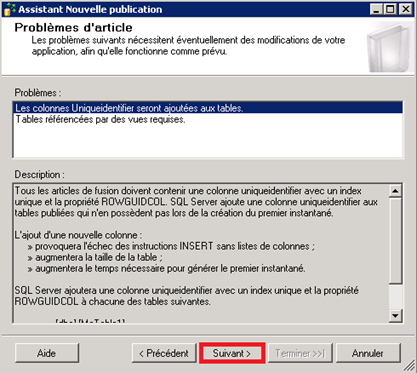
Ce qu’il faut savoir c’est que s’il existe un article référençant un objet (table, vue, index…) non sélectionné dans la liste des articles à répliquer, alors ledit objet doit obligatoirement être également sélectionné en tant qu’article (ce qui nécessitera un retour à l’étape précédente). Dans notre exemple précis, seules nos vues référencent d’autres objets.
Et du côté des contraintes, des colonnes de type Uniqueidentifier seront rajoutées pour le bon déroulement de la réplication de fusion. Par contre, cela peut avoir un impact potentiel non seulement sur la taille des tables (et donc la durée du snapshot) en rajoutant au moins 16 octets par ligne, mais également sur les requêtes d’insertion du fait du nombre de colonnes différentes. Il est donc crucial d’adapter le code source de ses requêtes et de les tester avant toute mise en production d’une réplication de fusion.
| Notons qu’en cas de suppression de la publication de fusion, toutes les colonnes de type Uniqueidentifier qui furent automatiquement créées seront également supprimées. |
-
Filtre des lignes des tables à répliquer :
Vu que l’on ne compte pas filtrer les lignes de nos tables ou vues, on peut ignorer cette étape.
-
Planification du travail du Snapshot Agent :
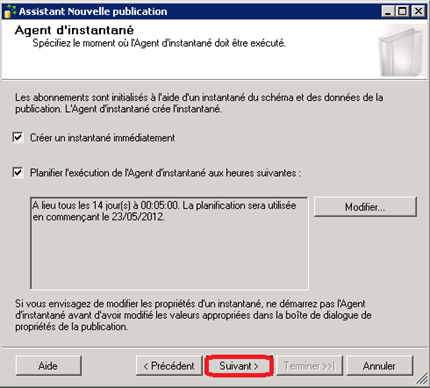
Par défaut, le Snapshot Agent est planifié pour se lancer une fois toutes les deux semaines (fréquence bihebdomadaire), à 0h05. Et vu que ceci correspond à nos besoins, aucun changement n’est à effectuer à cette étape de la configuration.
| Notons toutefois qu’un lancement manuel peut être possible si l’on souhaite, par exemple, que certaines nouvelles structures de données soient répliquées (indexes, etc…). Mais toutefois, les recréer manuellement sur les bases concernées est une bonne pratique si le snapshot est susceptible de durer longtemps ou d’impacter les performances. |
On n’oublie pas, si possible, de laisser l’assistant créer un snapshot de la base de publication après la configuration.
-
Configuration de la sécurité du Snapshot Agent :
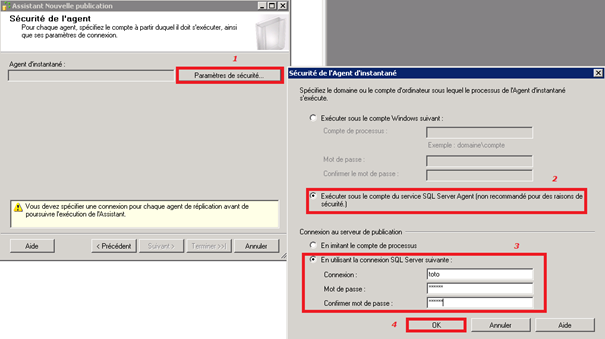
On choisit de laisser le Snapshot Agent s’exécuter avec le compte d’exécution du SQL Agent. En outre, on spécifie que le login SQL toto (préalablement créé sur l’instance hébergeant la base de publication) sera utilisé pour se connecter à l’éditeur (ou serveur de publication).
-
Choix du comportement de l’assistant post-configuration :
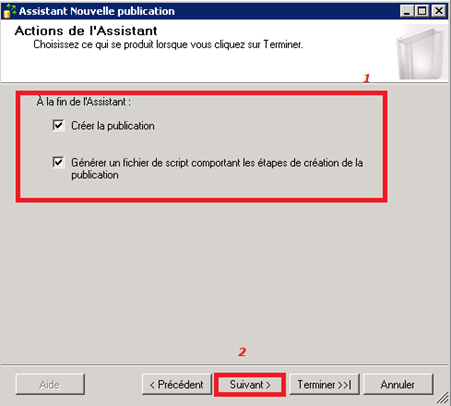
On n’oublie pas de choisir de générer le script de configuration de l’éditeur après configuration par l’assistant. Un tel script pourra être utile pour toute reconfiguration de l’éditeur en cas de sinistre ou réutilisation ailleurs.
-
Spécification du chemin d’accès et du nom du fichier de configuration de l’éditeur :
Le chemin d’accès choisi et le nom du script sont, bien sûr, arbitraires. Il faudra conventionnellement placer le fichier de configuration de la publication dans un dossier dédié.
-
Spécification du nom de la publication, validation et lancement :
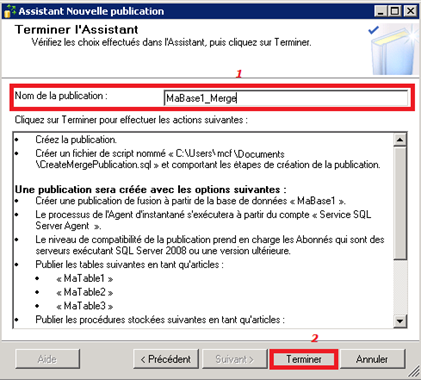
Appelons notre publication MaBase1_Merge.
- Confirmation du bon déroulement de la configuration :

Au sein de l’explorateur d’objets de SSMS, on peut noter la présence de la publication fraîchement configurée pour l’instance SRV-SQL01 dans la liste des publications locales :
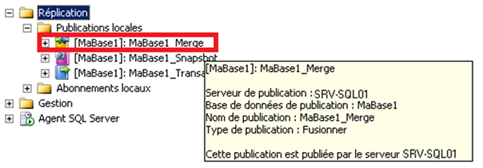
En plaçant la souris sur la publication, on peut lire sa description.
Du côté des jobs, on y trouve le job d’exécution du Merge Agent (SRV-SQL01-MaBase1-Merge-7) et celui du Snapshot Agent (SRV-SQL01-MaBase1-1) de la réplication transactionnelle que l’on vient de créer :
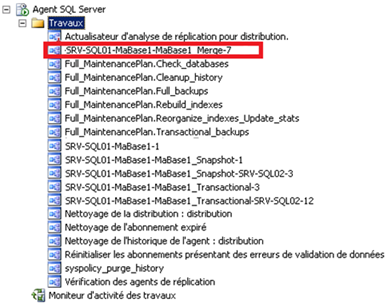
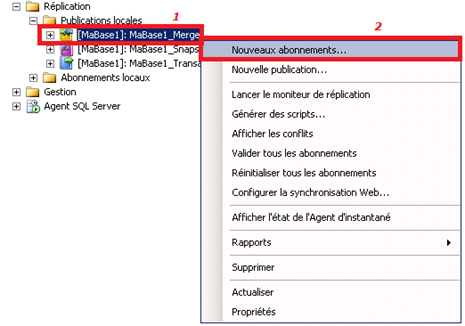
Il reste désormais à créer les abonnés MaBase5 et MaBase3. Pour ce faire, toujours au sein de l’instance de publication SRV-SQL01 :
-
Lancement de l’assistant de configuration de nouveaux abonnements :
Une fenêtre de bienvenue s’ouvrira :
-
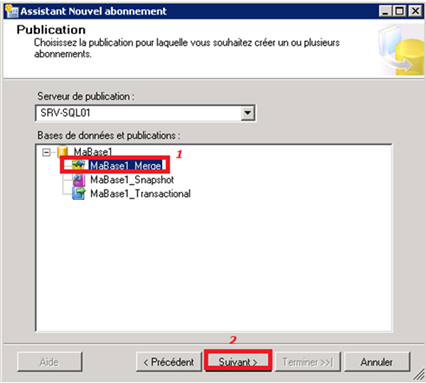
Sélection de la publication MaBase1_Transactional préalablement créée sur le serveur de publication:
-
Choix du mode de récupération :
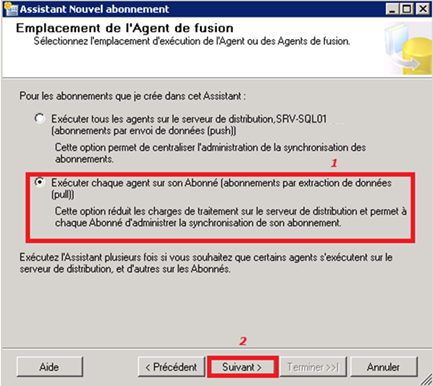
On opte pour le mode pull, ce qui signifie, rappelons-le, que nos abonnés récupéreront eux-mêmes les données via le Merge Agent.
-
Sélection des abonnés (serveurs de souscription et bases abonnées MaBase5 et MaBase3) :
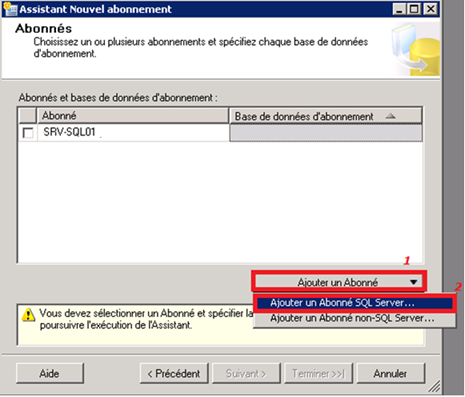
Après ajout de l’abonné (instance SRV-SQL02) et sélection de la bonne base MaBase5, on effectue la même chose pour MaBase3 située sur SRV-SQL03 pour arriver au résultat suivant :
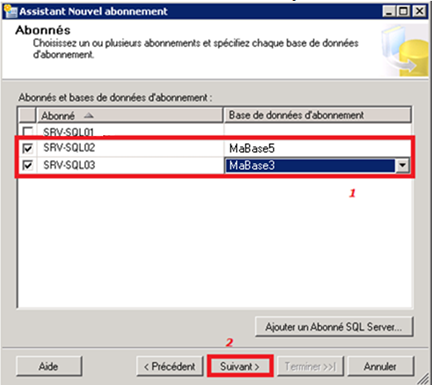
- Configuration de la sécurité du Merge Agent :
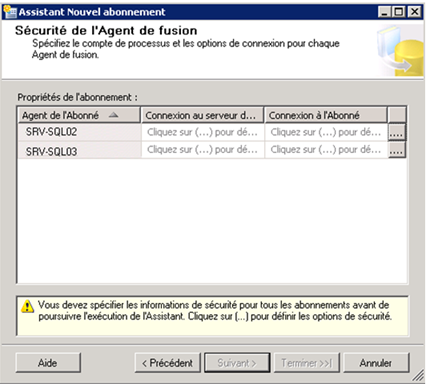
Pour chaque abonné, on choisit de l’exécuter dans le contexte du compte d’exécution du SQL Agent. En outre, on spécifie un login SQL de connexion vers l’instance où se trouve l’éditeur (SRV-SQL01) :

La configuration de la sécurité du Merge Agent pour chaque abonné donne l’aperçu suivant :
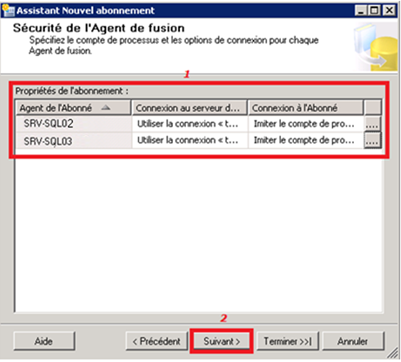
-
Planification du lancement du Merge Agent :
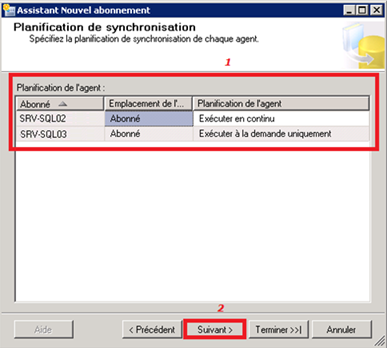
On choisit de définir la planification de l’agent de façon à ce qu’il puisse se lancer au continue (toutes les minutes) pour la base abonnée MaBase5 et à la demande pour l’abonné MaBase3.
-
Initialisation de l’abonnement :
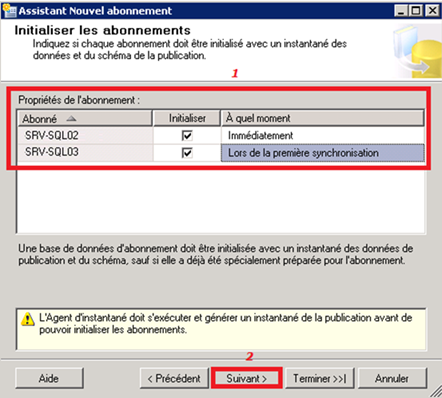
On peut choisir d’initialiser l’abonnement immédiatement (on sélectionne ce choix pour l’abonné MaBase5 d’SRV-SQL02) ou lors de la prochaine synchronisation (on opte pour cela pour l’abonné MaBase3 d’SRV-SQL03). On rappelle qu’un snapshot a été configuré plus haut.
-
Choix du type d’abonnés :
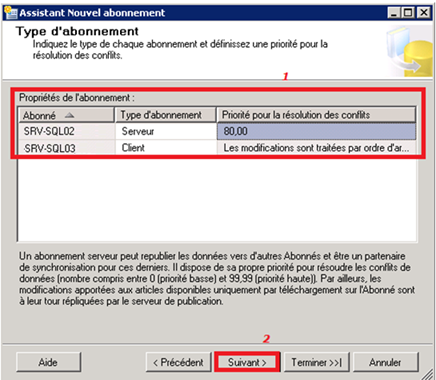
On choisit de spécifier l’abonné sur SRV-SQL02 comme serveur et l’abonné sur SRV-SQL03 comme client. Et pour le niveau de priorité pour la résolution des conflits, on donne arbitrairement 80 pour le serveur abonné. Mais toutefois, sachant que tout client n’a pas de niveau de priorité, cela signifie que peu importe le niveau de priorité des autres abonnés, le premier, entre le serveur abonné et le client abonné, qui arrive vers l’éditeur aura remporté le conflit.
-
Choix du comportement de l’assistant post-configuration des abonnés :
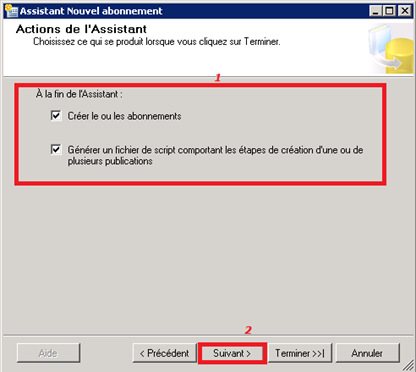
On n’oublie pas de préciser à l’assistant de générer le script de configuration des abonnés. Un tel script pourra être utile pour toute reconfiguration des abonnés en cas de sinistre ou réutilisation ailleurs.
-
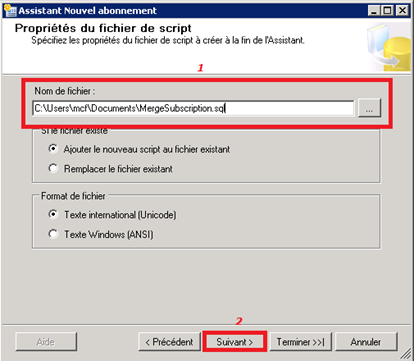
Spécification du chemin d’accès et du nom du fichier de configuration de l’abonné :
-
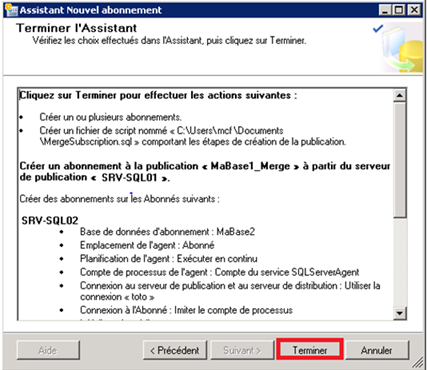
Résumé et validation de la configuration des abonnés :
-
Confirmation du bon déroulement de la configuration :
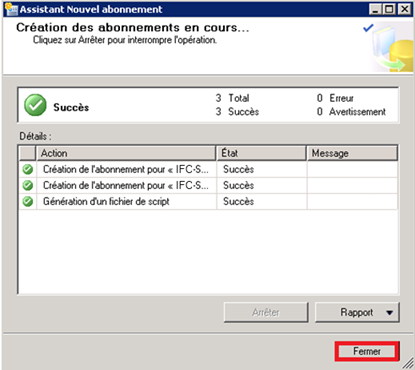
Au terme de nos configurations, au sein de SSMS, on peut souligner :
-
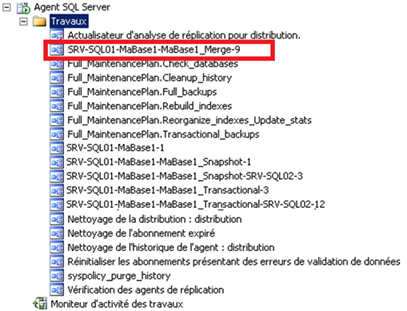
Sur l’instance SRV-SQL01 (éditeur) la présence d’un job dédié au Snapshot Agent :
-
Sur chaque instance des bases abonnées, un Merge Agent :
-
SRV-SQL02 (pour MaBase5) :
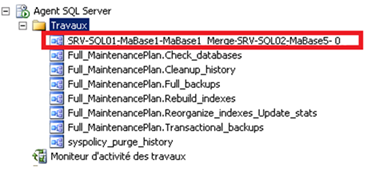
-
SRV-SQL03 (pour MaBase3) :
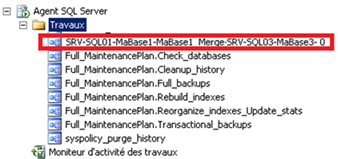
-
- Hormis dans chaque instance des bases abonnées (au sein de l’explorateur d’objets de SSMS : Réplication>Abonnements locaux), on trouve également sur l’instance SRV-SQL01 (éditeur), la présence de nos abonnés :
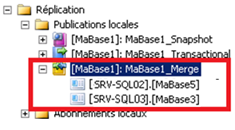
Pour aller plus loin…
Nous avons pu voir que la mise-en-place de la réplication merge avec SQL Server 2008 (R2) n’était pas insurmontable. Nous aborderons, très prochainement, quelques éléments d’audit et opérations avancées sur la réplication.

j’ai aimé cet article
cependant si l’agent est down pendant des jours comment mettre à jour les requêtes qui se sont exécutées entre temps ou bine c’est automatique
Bonjour Demba,
Une remise en service du Merge Agent permettra de récupérer les réplicats après qu’il ait évalué, avec ses triggers et tables systèmes (sur l’éditeur et l’abonné), tous les changements effectués sur les articles publiés. Mais toutefois, des erreurs peuvent éventuellement se manifester ou ne pas te permettre de tous les récupérer (suivant la volumétrie des données/objets à répliquer, les temps de latence, les éventuels changements DDL, la durée de rétention des transactions à répliquer (cas classique), le mode de publication choisi,… voire, simplement, la topologie de ta réplication de fusion et la façon dont tu gères les conflits…).
Si des problèmes de (re)synchronisation te martyrisent, tu peux jeter un coup d’oeil aux tables systèmes préfixées d’un MSmerge (voir lien en fin de commentaire), à ton Replication Monitor, à ton error log, à l’HistoryVerboseLevel , etc… suivant la complexité du problème constaté.
Plus de détails sur le fonctionnement d’un Merge Agent ici : https://mcherif.wordpress.com/2013/02/09/sql-server-replication-fonctionnement-de-la-replication-de-fusion/.
@+!
M.